Extract the facts that matter
Capture fields, clauses, tables, parties, dates, obligations, and entities from contracts, filings, reports, forms, and scans

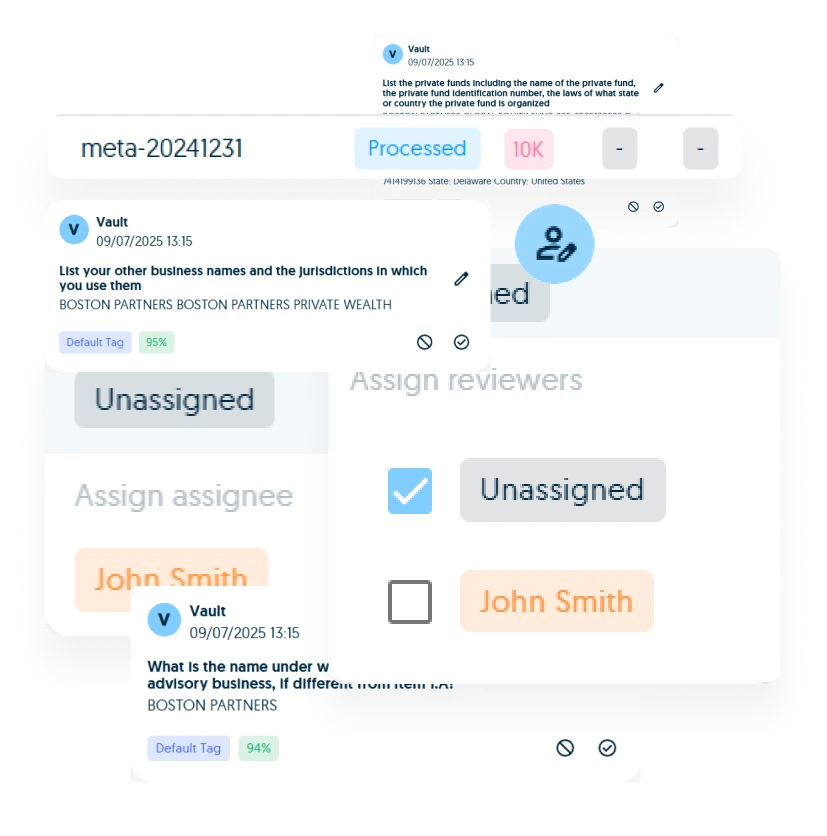
Extract facts from regulated documents and tie every answer to source, confidence, reviewer state, and audit trail.




[VAULT IN PRODUCTION]
Vault is the extraction and evidence layer for teams that need source backed answers, reviewer control, and downstream activation across Records, Workflows, Agents, and enterprise systems
Capture fields, clauses, tables, parties, dates, obligations, and entities from contracts, filings, reports, forms, and scans
Preserve source snippets, document location, confidence, version history, and reviewer decisions behind every extracted fact
Route low confidence answers, missing evidence, risk flags, and policy exceptions to the right reviewers before approval
Publish validated data into Records, Workflows, Playbooks, Agents, APIs, MCP tools, and system integrations
Vault supports the full operating path: ingest, extract, review, approve, and activate. Teams can standardise repetitive document processes without losing human oversight or auditability
Upload files or connect storage sources for contracts, PDFs, forms, spreadsheets, and scans
Use schemas, questions, tags, and models to identify the facts each workflow needs
Review evidence, confidence, assignments, approvals, changes, and access history
Send approved outputs to Records, reports, exports, workflows, agents, and integrations
Support SAML or MFA SSO, role based access, audit exports, SIEM ready logs, VPC or private deployment options, and custom support SLAs where required
Use Vault for customer due diligence evidence packs, contract intelligence, document audits, compliance reviews, procurement records, financial crime operations, and data entry automation
